MCP Server for Data Access: The Future of Analytics?
After spending some time with Anthropic’s Model Context Protocol (MCP), I’m cautiously optimistic about what might be a fundamental shift in how we interact with data. MCP promises to be the “USB-C port for AI applications”: a standardized way for LLMs to access external data and tools. While the protocol itself may seem like yet another abstraction layer, the bigger question is whether we’re witnessing the early stages of LLMs becoming the primary interface for data exploration.
To test this in practice, I built an NYC 311 Data MCP Server that exposes 3.5 million New York City service requests from 2024, enabling LLMs to interact with the data. The server lets AI assistants run read-only SQL queries against the full dataset: complaint types, geographic patterns, temporal trends. It’s built on DuckDB for performance and includes some security guardrails to prevent dangerous operations.
The bottom line: It works surprisingly well for basic exploratory data analysis, and raises interesting questions about whether traditional dashboards and BI tools might eventually give way to conversational analytics.
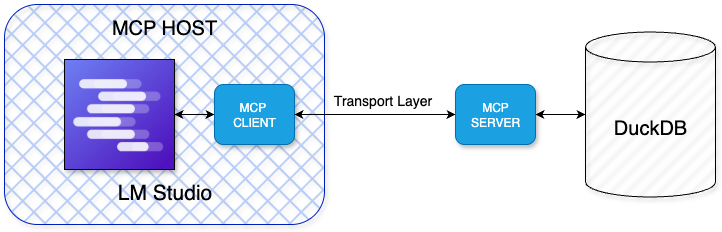
MCP Architecture
MCP uses a client-server architecture where the host (Claude Desktop, LM Studio, VS Code, etc) coordinates everything and enforces security, while clients maintain isolated sessions with servers that expose data through standardized primitives.
The good news is that servers are isolated from each other, ensuring they cannot access the full conversation history. Capability negotiation occurs upfront, allowing you to understand what features are supported before proceeding. While this adds complexity compared to a simple REST endpoint, MCP offers a lightweight and practical standard for tool interoperability. However, as MCP is still in its early stages and evolving rapidly, its long-term adoption remains uncertain.
NYC 311 Data MCP Server
To test this concept, I built an MCP server using the FastMCP framework with a DuckDB backend optimized for analytics requests. The server provides access to the full 2024 NYC 311 service requests dataset, comprising 3.5 million records with detailed location data (borough, ZIP, latitude/longitude), request specifics, and temporal information.
The core functionality centers around a query_data tool that executes read-only SELECT queries, plus a schema resource that provides table structure information. Security guardrails block SQL operations altering data (DROP, DELETE, UPDATE, INSERT, ALTER, CREATE, TRUNCATE, EXEC) and enforce LIMIT clauses for SELECT * queries. This allows the LLM to safely explore the dataset without risking accidental data corruption or excessive resource usage.
Testing with Real Data: Natural Language to SQL
The complete code to test this out is available in the markusos/llm_duck repository.
Setting this up requires Python 3.9+, the uv package manager, and an MCP-compatible client. LM Studio 0.3.17+ supports MCP by editing ~/.lmstudio/mcp.json, and tool calls show confirmation dialogs for security by default.
mcp.json:
{
"mcpServers": {
"311_data": {
"command": "uv",
"args": [
"--directory",
"/ABSOLUTE/PATH/TO/llm_duck",
"run",
"run_mcp_server.py"
]
}
}
}
After setting up the MCP configuration and loading Google’s gemma-3-27b LLM model into LM Studio, the model automatically discovered my MCP server. When prompting, the LLM began exploring the NYC 311 dataset. Without the need for manual SQL writing, it generated queries to uncover patterns across the 3.5 million records. DuckDB’s columnar storage handled the analytical workload efficiently, while the MCP layer added minimal overhead.
The assistant successfully analyzed complaint patterns, handled missing data gracefully, and even generated simple aggregations on demand. While these capabilities—basic text-to-SQL conversion and query execution—are impressive, MCP provides a crucial advantage: it establishes a standardized framework for LLMs to interact seamlessly with multiple tools, diverse data sources, and complex workflows.
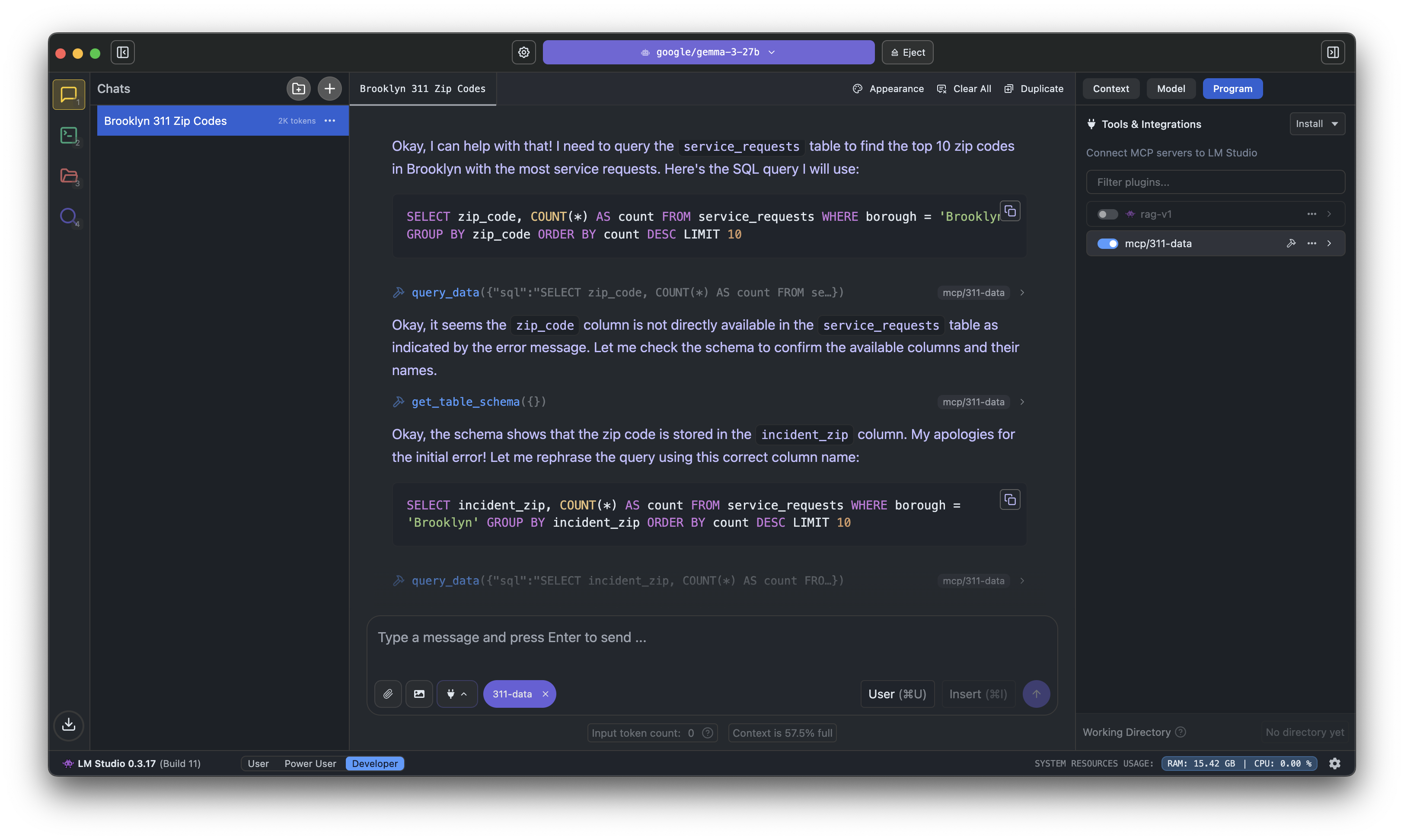
During testing of the MCP server with LM Studio and the google/gemma-3-27b model, the AI assistant successfully generated SQL to aggregate data, such as identifying the Zip codes with the most service requests in Brooklyn. When encountering invalid column names, the LLM utilized the schema resource to understand the correct structure and re-queried the data. This highlights how LLMs can leverage structured metadata and iterative refinement to enhance query accuracy, representing a significant advancement beyond basic text-to-SQL conversion.
SELECT
incident_zip,
COUNT(*) AS count
FROM service_requests
WHERE borough = 'Brooklyn'
GROUP BY incident_zip
ORDER BY count DESC
LIMIT 10
What’s particularly impressive is how the LLM can enrich raw query results with contextual information not stored in the database. For example, it translates ZIP codes into recognizable neighborhood names, making the data more meaningful to users.
| ZIP Code | Neighborhood Name | Service Request Count |
|---|---|---|
| 11213 | Sunset Park | 849 |
| 11203 | Williamsburg | 765 |
| 11216 | Bushwick | 746 |
| 11206 | Bed-Stuy (Bedford–Stuyvesant) | 738 |
| 11211 | Greenpoint | 735 |
| 11209 | Crown Heights | 724 |
| 11217 | Kensington | 687 |
| 11221 | Fort Greene/Clinton Hill | 653 |
| 11205 | Park Slope | 649 |
| 11233 | Flatbush | 648 |
The system works well for natural language to insights without manual SQL writing. While someone fluent in SQL could write these queries more accurately and efficiently, LLMs with MCP enables individuals without SQL expertise to access and interact with data in ways that were previously inaccessible, opening up new possibilities for data exploration.
LLMs as the New Dashboard?
This MCP server builds on my previous work categorizing NYC 311 requests using local LLMs, but represents a fundamental shift toward conversational analytics. Where traditional BI tools require pre-built charts and fixed queries, LLM-powered analytics enables dynamic exploration through natural language.
The implications are profound. Instead of building dozens of dashboard widgets to answer specific questions, we might soon have AI assistants that augment dashboard capabilities to instantly generate insights from natural language queries. Want to see “noise complaints by neighborhood during summer weekends”? No need to pre-define that visualization. The LLM constructs the query, executes it, and explains the results.
Rather than clicking through dashboard filters and pivot tables, analysts could simply describe what they want to understand and let the AI handle the technical translation. This represents a fundamental shift from static, pre-built visualizations to dynamic, conversation-driven data exploration.
What’s particularly interesting is how this complements my earlier batch processing work. Where I previously used LLMs to transform and categorize data at scale, this MCP server demonstrates LLMs as interactive query engines. We’re seeing the emergence of a complete LLM-powered analytics stack: batch processing for data preparation and real-time conversations for data consumption.
Challenges and Opportunities Ahead
While this experiment demonstrates the potential for LLM-powered analytics, several challenges remain before conversational data analysis becomes mainstream.
LLM reliability issues surfaced during testing that highlight the technology’s current limitations. The AI assistant sometimes failed to generate correct tool calls, occasionally made up tool responses instead of using the actual MCP server, and would ignore parts of the tool output while generating responses. These aren’t just minor bugs. They represent fundamental challenges with LLM reliability that could undermine user trust in production environments.
Technical standardization is still evolving. MCP provides one approach, but the ecosystem is fragmented. Today you might build an MCP server, tomorrow it could be a different protocol entirely. The good news is that the underlying capability (LLMs generating and executing SQL) works regardless of the transport mechanism.
Security and governance require careful consideration. Unlike traditional dashboards with fixed queries, LLM analytics can generate arbitrary SQL. This flexibility is powerful but demands robust guardrails, especially with sensitive enterprise data. My implementation blocks some dangerous operations, but determined users could still extract large datasets through their prompts.
Data complexity scales quickly beyond simple schemas. My single-table NYC 311 dataset works relatively well, but enterprise scenarios with hundreds of tables, complex joins, and business logic require sophisticated semantic layers. The LLM needs to understand not just what data exists, but what it means and how metrics should be computed.
User expectations will need to evolve too. Traditional dashboards set clear expectations about what questions can be answered. Conversational analytics promises infinite flexibility, but users will need to learn how to ask good questions and interpret probabilistic responses from LLMs that might misunderstand context or hallucinate results.
Despite these challenges, the trend toward LLM-powered analytics feels inevitable. As models become more capable and data infrastructure adapts, the friction of asking questions will continue to decrease. The question isn’t whether this will happen, but how quickly organizations can adapt their data practices to support it and how fast foundational LLM models keep improving.
Observations and Future Potential
My trial with the NYC 311 Data MCP Server demonstrates both the promise and practical challenges of LLM-powered analytics. Similar to my initial impressions of AI coding assistants, there’s an immediate sense that we’re witnessing the early stages of a fundamental shift in how humans interact with data.
The system excels at translating natural language questions into SQL queries and providing immediate insights without manual coding. The standardized interface could theoretically work across different AI assistants, creating a unified way to access organizational data. Most importantly, it hints at a future where business users can explore data directly through conversation rather than relying on pre-built dashboards or technical teams.
However, significant challenges remain. The infrastructure feels heavyweight for simple use cases, and real-world adoption patterns are still unclear. More critically, scaling beyond simple schemas requires sophisticated semantic layers that most organizations haven’t built yet.
The honest assessment is that we’re still in the early experimental phase, but the direction seems clear. As LLMs become more capable and data infrastructure evolves to support them, conversational analytics will likely become the norm rather than the exception. Traditional dashboards may not disappear entirely, but they’ll increasingly serve as fallbacks rather than primary interfaces.
For now, MCP represents one approach to standardizing this future, but the more important trend is the underlying shift toward AI-powered data exploration. Whether through MCP, enhanced REST APIs, or entirely different protocols, the age of conversational analytics is beginning.