MongoDB Community Edition: Vector Search for Everyone
I’ve been itching to try MongoDB’s vector search ever since I saw it demoed at MongoDB.local NYC back in September. But here’s the thing: until recently, it was Atlas-only. If you wanted to build a RAG application or experiment with semantic search, you either paid for Atlas or jury-rigged something with Pinecone or Weaviate alongside your MongoDB instance. It works, but it always felt like a duct taped solution.
Then MongoDB 8.2 Community Edition dropped with vector search in public preview, and I immediately spun up a demo project. This isn’t just a nice-to-have feature. It fundamentally changes what you can build locally. No more “well, I’d love to test this, but I need to sign up for their cloud service first.”
What Actually Changed
Here’s what MongoDB added to the free, self-managed Community Edition:
$vectorSearch- Semantic similarity search right in your aggregation pipelines$search- Full-text keyword search with fuzzy matching$searchMeta- Metadata and faceting for search results- mongot - A separate search binary that handles the indexing (runs alongside mongod)
The key part is functional parity with Atlas. Same APIs, same aggregation operators, same everything. You’re not getting a watered-down version. This is the real deal, just running on your own hardware.
Setup
I built a Wikipedia search demo to test this out properly. The stack is pretty straightforward:
- MongoDB 8.2 and mongot running in Docker
- LM Studio for generating embeddings locally (using Nomic Embed)
- A Python app to ingest Wikipedia articles and run searches
The interesting bit is that you need both mongod and mongot running. Mongot is the search server. It handles the indexing and similarity calculations while mongod stores the actual data. They talk to each other behind the scenes.
One gotcha: MongoDB needs to run as a replica set, even if it’s just a single node. The search features require this. Not a huge deal, but it means your docker-compose setup needs a few extra lines to initialize the replica set.
Here’s the basic docker-compose structure:
services:
mongod:
image: mongodb/mongodb-community-server:8.2.0-ubi9
command: mongod --replSet rs0
ports:
- 27017:27017
mongot:
image: mongodb/mongodb-community-search:0.53.1
ports:
- 27028:27028
depends_on:
- mongod
That’s it. No Atlas credentials, no external services. Everything runs locally.
For more details, check out the official MongoDB quick start guide: MongoDB Vector Search Quick Start.
Setting Up the Indexes
The first thing you need to do is create search indexes. MongoDB needs these to know how to handle your searches. Kind of like telling it “hey, these vectors should be searchable by similarity” or “these text fields should support keyword matching.”
Vector Search Index
For vector search, you create an index that knows how to handle high-dimensional embeddings. In my case, I’m using 768-dimensional vectors from the Nomic Embed model:
from pymongo.operations import SearchIndexModel
definition = {
"fields": [
{
"type": "vector",
"path": "embedding",
"numDimensions": 768,
"similarity": "cosine"
}
]
}
model = SearchIndexModel(
definition=definition,
name="vector_index",
type="vectorSearch"
)
collection.create_search_indexes([model])
The numDimensions has to match your embedding model. I’m using 768 because that’s what Nomic Embed outputs. The similarity metric is usually cosine for text embeddings. It’s what works best for semantic similarity.
Text Search Index
For full-text keyword search, it’s even simpler. You can just use dynamic mapping and MongoDB will index all your string fields:
definition = {
"mappings": {
"dynamic": True
}
}
model = SearchIndexModel(
definition=definition,
name="text_search_index",
type="search"
)
collection.create_search_indexes([model])
That’s it. MongoDB handles the rest.
The Data Structure
I split Wikipedia articles into two collections: one for article metadata and one for searchable chunks. The chunks collection is where the magic happens:
{
"page_id": 12345,
"title": "Machine Learning",
"chunk_index": 0,
"section": "Introduction",
"text": "Machine learning is a method of data analysis...",
"embedding": [0.123, -0.456, 0.789, ...], # 768-dim vector
"token_count": 256
}
Each chunk is about 512 tokens of text (roughly a few paragraphs), and each one gets its own embedding vector. This chunking strategy is important. You can’t just embed entire Wikipedia articles. They’re too long, and you lose granularity. By chunking, you can find the specific section that’s relevant to a query.
I’m using LM Studio to generate the embeddings locally. The Python code uses the lmstudio package to interface with the embedding model:
import lmstudio as lms
# Load the embedding model
model = lms.embedding_model("text-embedding-nomic-embed-text-v1.5@q8_0")
# Generate embedding
embedding = model.embed("Your text here")
The embeddings go right into MongoDB as arrays. No special format needed, just a list of floats in the embedding field.
Vector Search: Semantic Similarity in Action
This is where things get interesting. Vector search is all about semantic similarity. Finding documents that mean the same thing, not just documents that contain the same words.
The query is an aggregation pipeline with the new $vectorSearch stage:
pipeline = [
{
"$vectorSearch": {
"index": "vector_index",
"path": "embedding",
"queryVector": query_embedding,
"numCandidates": 100,
"limit": 10
}
},
{
"$project": {
"title": 1,
"text": 1,
"score": {"$meta": "vectorSearchScore"}
}
}
]
results = list(collection.aggregate(pipeline))
You embed your query text (same way you embedded the documents), then pass that vector to $vectorSearch. It finds the closest matches using cosine similarity.
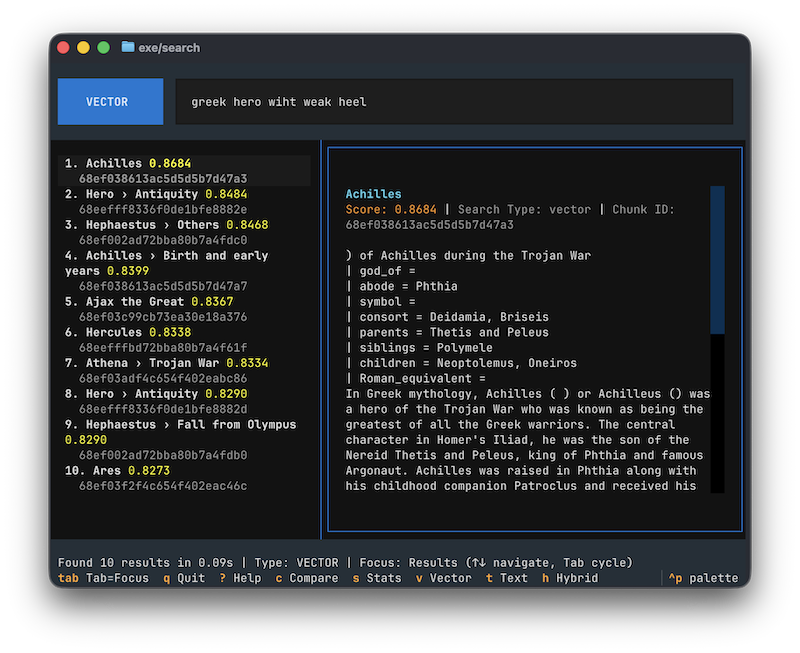
The results are genuinely impressive. I can ask “Greek hero with weak heel?” and it pulls up relevant chunks about Achilles and the Trojan War, even though I never mentioned his name. That’s the semantic part working. Conveniently, Achilles is one of the first articles loaded from the Wikipedia dataset, which makes it a perfect quick test to validate everything is working correctly.
One thing to note: numCandidates is how many documents it considers before narrowing down to your limit. Higher numbers give better results but are slower. I experimented a bit and set it to 10x the limit as a starting point.
Text Search: Good Old Keyword Matching
Sometimes you just want to find documents that contain specific words. That’s what $search is for: traditional full-text search with all the bells and whistles.
pipeline = [
{
"$search": {
"index": "text_search_index",
"text": {
"query": "Albert Einstein relativity",
"path": ["text", "title"],
"fuzzy": {"maxEdits": 2}
}
}
},
{"$limit": 10},
{
"$project": {
"title": 1,
"text": 1,
"score": {"$meta": "searchScore"}
}
}
]
results = list(collection.aggregate(pipeline))
The fuzzy matching is nice. It’ll catch typos and close variations. If someone searches for “Einstien” instead of “Einstein,” it still works.
Text search is faster than vector search and more predictable. If you know the exact term you’re looking for (like a person’s name or a technical term), text search is usually the better choice. But it doesn’t understand semantics. It’s just matching words.
Hybrid Search: The Best of Both Worlds
The really cool part is combining both approaches. You run a vector search and a text search, then merge the results using something called Reciprocal Rank Fusion (RRF). It’s a way of saying “if a document shows up high in both result sets, it’s probably really relevant.”
Here’s the basic idea:
# Run both searches
vector_results = vector_search(query, limit=20)
text_results = text_search(query, limit=20)
# Calculate RRF scores
rrf_scores = {}
for rank, result in enumerate(vector_results, 1):
rrf_scores[result.id] = 1.0 / (60 + rank)
for rank, result in enumerate(text_results, 1):
if result.id in rrf_scores:
rrf_scores[result.id] += 1.0 / (60 + rank)
else:
rrf_scores[result.id] = 1.0 / (60 + rank)
# Sort by combined score
final_results = sorted(rrf_scores.items(), key=lambda x: x[1], reverse=True)
This gives you the best of both worlds. Documents that match semantically and contain the right keywords get boosted to the top. It’s surprisingly robust. I’ve found it works well without much tuning.
You can also do weighted combinations if you want more control (e.g., 70% vector, 30% text), but RRF is usually good enough.
What This Enables
The real win here is RAG (Retrieval-Augmented Generation). You can now build a complete RAG pipeline without leaving MongoDB:
- User asks a question
- You embed the question and do a vector search
- You retrieve the top 3-5 relevant chunks
- You feed those chunks as context to an LLM
- The LLM generates an answer grounded in your data
This is the “memory” concept from the MongoDB.local keynote. Giving AI agents access to your data in a way that’s fast, relevant, and doesn’t require syncing between multiple databases.
And because it’s all in MongoDB, you get:
- Transactional consistency - No sync lag between your main DB and your vector store
- Simple architecture - One database, one query language, one connection string
- Metadata filtering - Combine vector search with traditional filters (e.g., “find similar articles, but only in the ‘Science’ category”)
Performance
The search performance itself is solid. Vector search typically returns results in under 100ms for 10 results. Text search is even faster at around 20-30ms. Hybrid search is just the sum of both plus some merging logic.
The bottleneck is embedding generation. Processing 10,000 Wikipedia articles for ingestion into MongoDB takes hours on consumer hardware, and parsing and embedding the entire Wikipedia dump would take days. That’s not a MongoDB problem though. That’s just how long it takes to run text through an embedding model locally. Once your data is indexed, queries are fast.
Wrapping Up
Vector search in MongoDB Community Edition changes the local development game. Before this, building a RAG application meant juggling multiple databases: MongoDB for your data, Pinecone or Weaviate for vectors, and some sync mechanism to keep them aligned. Now it’s just MongoDB. One connection string, one query language, one place where everything lives.
The fact that this is in the free Community Edition matters. No monthly bills, no vendor lock-in. You can prototype locally, understand exactly how it works, and decide later whether you want to move to Atlas or keep running it yourself. That’s the kind of flexibility that makes experimenting with new features actually happen instead of staying on the “maybe someday” list.
I’ve put the complete demo project on GitHub at markusos/mongo-search-demo. It includes the Docker Compose setup, Wikipedia ingestion pipeline, LM Studio integration, and an interactive CLI for testing all three search modes. Clone it, run docker compose up, and a few additional setup steps, and you’ll have a working vector search system running locally in minutes. No cloud accounts required.